
Programmers have not always been fortunate enough for programming languages as understandable as those available today. Binary is the only language computers truly speak, and it is foreign to what humans are accustomed to using. Programs written in what is known as “higher-level” languages (those which are easier for humans to read) turn into a series of 1’s and 0’s computers can read. There are two main ways this can happen: compiling and interpreting.
1. Compiling
The job of the compiler is to translate a program to instructions specific to a type of computer, be it running Windows, MacOS, a Raspberry Pi, etc. Each of these has different hardware which can respond to different instructions, and a compiler only targets one of them at a time.
2. Interpreting
Interpreters are a bit different – they do not actually create another program to be executed but run programs themselves. It might seem strange that there would be two different ways for this to work. Compilers have this extra step of translating before executing, while interpreters run the code directly. A great example is when interpreters run Python code.
While these two techniques are similar in what they are trying to do (get programs to run), how they go about it is extremely different. One key difference is in terms of performance. Since a compiler targets a particular set of hardware, it can more intelligently apply optimizations to make the program more efficient. Though these are two different techniques, the majority of steps needed for both a compiler and an interpreter to go from human-written code to a program a computer can run are the same:

This process is generally broken into three sections: front-end, middle, and back-end. Where the front-end mainly deals with the structure of the program, the middle deals more with the meaning, and the back-end handles the lower level parts.
Scanning
The first step towards getting a program ready to run is called scanning. There are some things humans put in their programs which, for the most part, are only there, so the code is more readable (spaces, lines of code, etc.) It’s the job of the scanner to remove all of this and turn each meaningful part of the program into smaller pieces called tokens. These tokens are just like the words and punctuation used in traditional written and spoken languages. Take the following Python code:
def foo(a):
x = 2
This will get turned into a series of tokens something like:

In Python, the placing of spaces and lines is important, just like in some English writing (e.g., poetry), so the scanner won’t remove them because they do, in fact, have meaning. Now all of the unnecessary stuff has been removed; the process can continue with the next step: parsing.
Parsing
Programming languages, like all human languages, have a grammar that defines their structure, order, and the meaning of each word and symbol. In English, this might look something like:
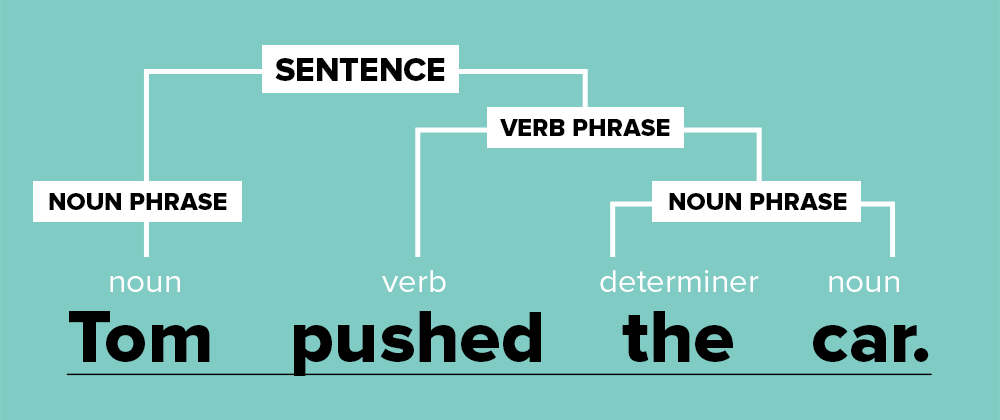
The primary goal of this phase is to generate what is called an Abstract Syntax Tree (AST). This is nothing more than a way to represent the program in a form easy for the interpreter to look at. While the AST is being created, the program will be checked to make sure it adheres to the grammar the language requires. Continuing with the previous example, this might get turned into a tree which looks something like:
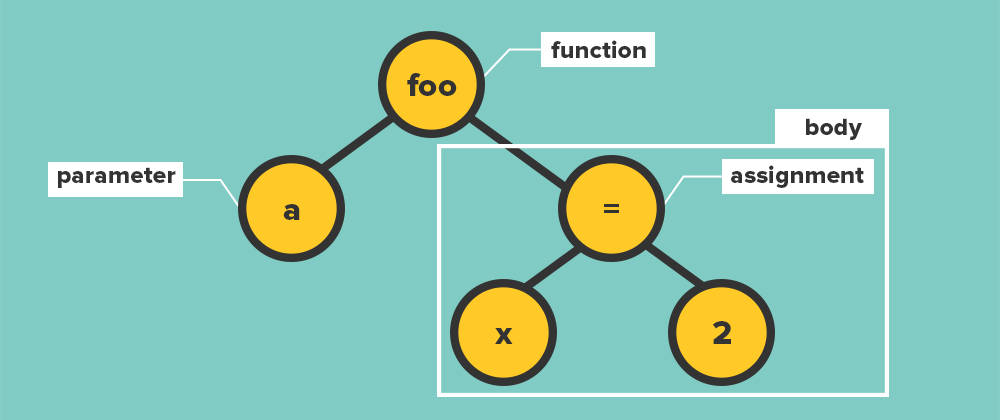
Assuming the program passes all the tests in the front-end, it is time to move to the middle.
Semantic Analysis & Intermediate Representations
If parsing checks to make sure the program looks right, the next logical step would be to ensure the program makes sense. Does it try to add things which cannot be added together? Does it compare things which do not make sense to compare? During this phase, the interpreter will also create some way to find variables the program is using. This way when it comes across a statement, it knows exactly where to find what it needs.
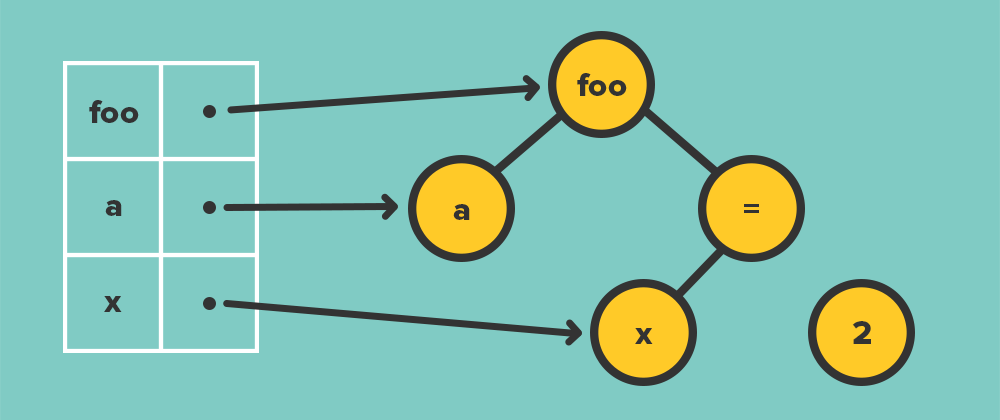
Armed with this new table (often called a symbol table) it is time to generate something the back end can use. That’s generally called an intermediate representation (IR), and it’s the final part of the middle portion. One key advantage of creating this IR is that almost any language can now be translated into it and leverage all the power of the back-end. This starts with optimization.
Optimization
Programmers are not ideal. Writing code which is maintainable and easy to understand is challenging. Not only is writing good code difficult, but it’s often the case that code which is easy to understand comes at the cost of code which runs efficiently. It’s the job of the optimizer to take the understandable human-written code and make it better.
There is an incredible amount of complexity and magic to this step – code might get reorganized, parts might get removed and rewritten. Anything to make the program run faster, use less memory, consume less power or whatever “better” means for that particular program. Now the program has been optimized, and it is time to create something that can be executed.
Code Generation
Depending on how the program is being executed, the code that is being generated in this step will be very different. While there are many different ways of running a program, one popular way for interpreters is to generate what is known as bytecode.
While generating bytecode is technically “compiling” it’s not the code that is meant to run on an actual physical machine, so it’s separate from what a classic compiler is doing. That is a language interpreters understand, and it tells them what actions need to be performed. Bytecode will often be run on what is known as a virtual machine (VM). These VMs have everything that makes up a real computer, but it is all software, not hardware. Now any bytecode which the VM understands can be run on any computer which can use the VM. As an example of what this might look like ponder the previous Python code and what the bytecode one of the VMs that runs Python uses:
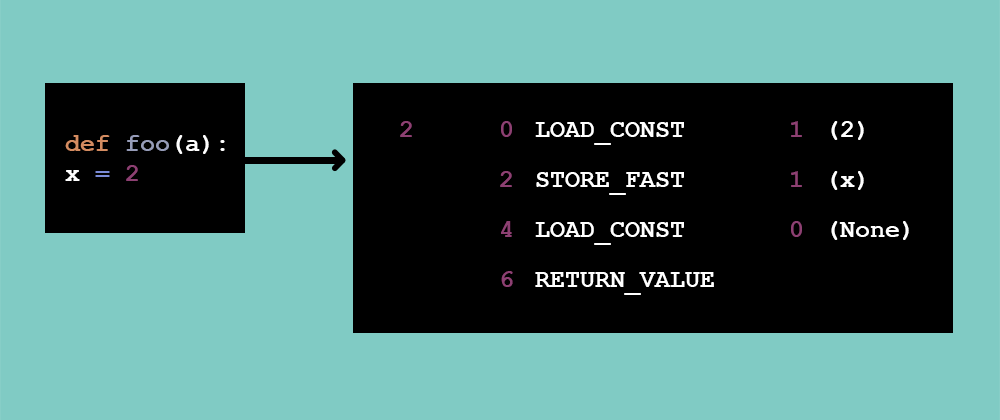
This bytecode does not look as pretty as the code it came from, but this is the whole point – take what a human wants to read and turn it into what a computer knows how to read. Now that the interpreter has this, it can start running the program, line by line.
The journey has been long, but it is over. There are a lot of steps to get from what a programmer writes and how a computer runs it, this being only one of many ways. In the end though, looking at each step individually it is not so bad. Most programmers will never have to deal with this, but not understanding how programs run can lead to not fully understanding programming.
Some other interpreted languages:
JavaScript, PHP, C#, Ruby, R
Resources:
English grammar image
https://hackernoon.com/compilers-and-interpreters-3e354a2e41cf
https://opensource.com/article/18/4/introduction-python-bytecode
http://craftinginterpreters.com/a-map-of-the-territory.html
https://devguide.python.org/compiler/
https://en.wikipedia.org/wiki/Optimizing_compiler#SSA-based_optimizations
https://en.wikipedia.org/wiki/Virtual_machine
Source: https://www.codingdojo.com/blog/interpreters-run-python-code



