
SPONSORED BY MONGODB
With the advent of large-language models, everyone is looking to enable conversational interfaces within their programs, whether they are search, code generation, or data analysis. One of the foundational technologies for this is the vector embedding, which takes a token of natural language—document, sentence, word, or even images, video, or audio—and represents it as a vector, letting any app traverse its language model like a map.

A vector embedding is essentially a fixed-sized array of floating point numbers. This means it can be stored in a few kilobytes of space in any database. While this may not seem like much, if you need to store and compare thousands of embeddings, the numbers will quickly add up. Sooner rather than later, you’d realize that the database you chose hasn’t been built with vectors in mind.
Additionally, it is highly unlikely that you’d use embeddings in isolation. To continuously generate embeddings for your data, you need to integrate your database with an embedding model, such as Google Cloud’s textembedding-gecko model. textembedding-gecko is a transformer-based model trained on a massive dataset of text and code. It can generate high-dimensional vectors that capture both the semantic meaning and the context of the words. For example, this integration can be used to continuously create vector embeddings for customer reviews and product ratings. The embeddings can then be used to improve the performance of your customer churn prediction model, which could help you to identify customers who are at risk of leaving your business.
Without a doubt, vector embeddings are a powerful tool for representing data and an integral part of many AI-powered apps. But storing and querying them efficiently can be a challenge.
One solution is to use a specialized vector database. But this introduces a whole new set of challenges: from synchronizing your operational and vector databases, through learning a new technology, all the way to maintaining and paying for an extra product.
What if you could store vectors in your existing operational database and still get the performance benefits of a specialized vector store? What if you choose a data platform that supports storing and querying vectors and seamlessly integrates with one of the best AI cloud platforms—Google Cloud? You can use MongoDB Atlas Vector Search and keep the performance benefits of an optimized vector store without the hassle of managing a separate database!
MongoDB Atlas is a fully-managed developer data platform offering integrations with a variety of Google Cloud AI services. It comes with a wide range of features including global deployments, automated data tiering, and elastic serverless instances. Vector Search is a new feature of that allows you to store, index, and search through vector embeddings efficiently. It is built on top of MongoDB Atlas’s powerful query engine, so you can use the same familiar syntax to query your vector data.
Efficient vector storage in your operational database
MongoDB Atlas has supported full-text search since 2020, but only using a rich keyword matching algorithm. More recently, we started seeing people bolting on vector databases to their MongoDB Atlas data, converting the data there into text embeddings. Their operational data lived in one place, and the vectors lived in another, which meant that there was a lot of syncing going on between the two solutions. That created an opportunity to reduce the overhead of those two tools and the inefficiency of the sync.
Customers were already using MongoDB Atlas to store chat logs from LLM-based chatbots. These bots create a lot of unstructured data, which has been our bread and butter. We’d already added chat log support, as our flexible schema can take in all of the additional prompts and responses generated through general usage. Our customers wanted to take all that chat data and feed it back into the model. They wanted to give their chatbots a memory. For that, we needed the vectors.
With vector search, developers using MongoDB Atlas can include their vector embeddings directly inside the documents in their database. Once customers have embedded their data all they need to do is define a vector index on top of the relevant field inside of their documents. Then they can use an approximate nearest neighbor algorithm via a hierarchical navigable small world (HNSW) graph with the same drivers and API that they use to connect to their database.
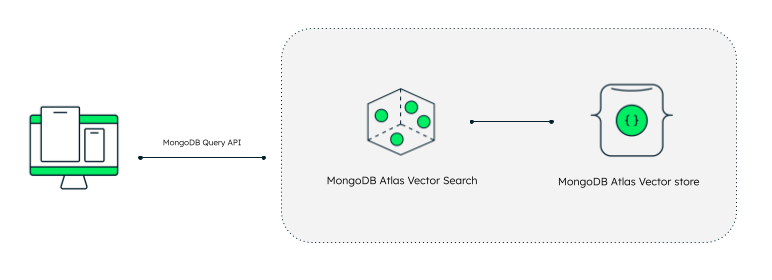
Now, in addition to the standard unstructured data, you can create an index definition on top of your collection that says where the vector fields are. Those vectors live right alongside the operational data—no syncing needed. This makes all your new chat log data available for approximate nearest neighbor algorithms. You’ll have to figure out an intelligent chunking strategy and bring your own embedding model, but that’s pretty standard if you’re looking to add data to a chatbot.
Every LLM is bounded by the training data it uses, and that training data has a cutoff date. With custom embeddings, customers can now provide up to date context for the model to use during inference. With the integrations built into frameworks like LangChain and LlamaIndex, developers can connect their private data to LLMs. Our community was so excited about the new capabilities in Atlas Vector Search that they provided the first commits to enable these frameworks.
Continuous generation of embeddings with MongoDB Atlas Triggers and Vertex AI
Storing your vectors in MongoDB Atlas comes with some added benefits. MongoDB Atlas is a lot more than deploying MongoDB to the cloud—it also includes a range of services for efficient data management. One of them is triggers—serverless functions that execute at predefined schedules or when a specific event occurs in your database. This makes it possible to automate the creation of embeddings for new data.
For example, let’s say you have a collection of products in your database. You want to create embeddings for each product so that you can perform semantic search for products and not just keyword search. You can set up a trigger function that executes whenever a new product is inserted into the collection. The function then calls Google Cloud’s Vertex AI API to generate an embedding of the product and store it back into the document.
You can also use triggers to batch the creation of embeddings. This can improve performance and lower costs, especially if you have a large number of documents to process. Vertex AI’s API allows for generating five text embeddings with a single API call. This means that you can create embeddings for 500 products with just 100 API calls.
Alternatively, you can set up a scheduled trigger that generates embeddings once a day. That’s a good option if you don’t need to create embeddings in real time.
By using triggers and the flexible Vertex AI APIs, you can automate the creation of embeddings for new data or even for data that has been updated.
Having a vector store within MongoDB Atlas enables some pretty great superpowers. But you may wonder why, if vector databases have been around for a little while already, you wouldn’t just use a purpose-built database for all your text embedding needs.
All-in-one vs. specialized tools
The reality is that you don’t even need a vector database to store vectors—you can store them in any database. They are arrays of floating point numbers, and any database can do that. But when you have millions or more, two challenges emerge: efficiently storing and querying them.
Storage
Firstly, having two databases instead of one means you have to keep both of them alive. You have to pay for their uptime and data transfer. You need to monitor both of them and scale their infrastructure. One data store running on one infrastructure with one monitoring setup is simpler. More dependencies, more problems, right? I’m sure your DevOps and SRE teams would appreciate having fewer items to keep an eye on.
Those two databases store two encodings of the same data, which means there will be syncing anytime something changes in the operational store. Depending on what your application is, you may be sending regular embedding updates or re-embedding everything. It’s an additional point of contact, which makes it an additional place to break down. Any friction or inconsistencies in the data can cause your users to have a bad time.
Queries
When running queries on vector databases, many people talk about K-nearest neighbor searches. They’re either talking about an exact search, which needs to be calculated at runtime, or an approximate search, which is faster but less accurate and loses some of the results on the margins. Either way, that requires two separate API calls: one for the search and one to retrieve the results.
When operational and vector data live right next to each other, it becomes a whole lot easier. You can filter, then search. The text embedding that enables semantic search and LLM-based applications is important, but so is the text that those vectors are based on. Combining the two helps create the applications that you want to use.
There’s an important part of this process that combines both storage and query issues, and that’s how you chunk the data to create the vectors. Chunking is how you break up larger pieces of text into smaller fragments so your search results can be granular. This process needs to happen as part of your data processing pipeline.
Imagine that you’re processing a book. When a user is searching for something, they probably don’t want to get the entire book back, and valuable meaning may get lost if you try to embed the entire piece of text in one vector. Most likely you will want to be able to point a user to a specific sentence or page within the book. So you’re not going to create a single embedding for the whole book—you’re going to chunk it out into chapters, paragraphs, and sentences. There’s a complex relationship between those chunks. Each sentence links back to the source data for that sentence, but it also links back to the paragraph, which links back to the chapter, which links back to the book. In the same way, you need to model your operational data effectively to get a set of vectors that link back to their sources. This data modeling can be most efficiently done within the data layer, not at the application layer via a framework like LangChain and LlamaIndex, which also requires storing these parent relationships in memory. As we’ve seen with some of the LLM hallucinations, verifying responses with sources can be key to making good applications.
Ultimately, that’s what we’re trying to do by combining vector data with operational data: create good applications.
Vector search use cases
We can talk ourselves blue about the benefits of storing vectors with your operational data, but we ponder a few use cases might help illustrate the effects. Here are two: restaurant filtering and a chat bot for internal documentation.
Restaurant filtering
Most restaurant listing platforms today have two separate sections: details about the restaurant like location, hours, and reviews. Both of them provide good, searchable data for anyone looking for a meal, but not all searches will be as effective if you just use keyword or vector searches.
Imagine you want comfort food in New York City. Maybe you want to search for “comfort food in New York City like mama made.” That query in a vector search could get you the comfort food you’re looking for, but it could also bring up results that aren’t in New York City.
If you were to take a naive approach to this problem, you might use what is called a “post filter.” In this naive scenario, you would return the 100 nearest neighbors from a vector search solution and then filter out any results that don’t happen to be in New York. If it just so happens that out of the 100 results you retrieve from the first stage of the previous example are all in Birmingham, Alabama, then the resulting query would provide zero results even though there are comfort food options in New York City!
With a solution like Atlas Vector Search that supports “pre-filtering,” you can filter the list of vectors based on location as you traverse the vector index, thereby ensuring you always get 100 results as long as there are 100 comfort food restaurants in New York City.
Search your knowledge base
One of the downsides of most LLM-enabled chat applications is that you can’t check their sources. They spit out an answer, sure, but that answer may be a hallucination, it may be dated, or it may miss the context of private information it needs to be accurate or helpful.
That’s where retrieval-augmented generation (RAG) comes in. This NLP architecture can give both a summarized answer based on your data and links to sources. Think of a situation where you have a bunch of internal documentation: for example, say you want to search to determine whether you’re eligible for dental insurance in a particular location. Because that is private information that only the dental insurance provider knows about, you’re going to have to manage the text-embedding process (along with storage and retrieval of the vectors) yourself. While the semantic search might get you the answer, you’ll want a reference to the source of the answer to confirm the accuracy of any LLM response.
In this scenario, your application will take the user’s query and send it to the vector search solution to find the relevant information. Once it has that relevant information it will construct a “prompt” that contains the question the user asked, the information received from the vector search, and any other parameters you want to use to make the LLM respond how you’d like (e.g. “respond politely”). Once that’s done, all of that information is sent to the LLM and the result is returned back to the application which can be presented to the user.
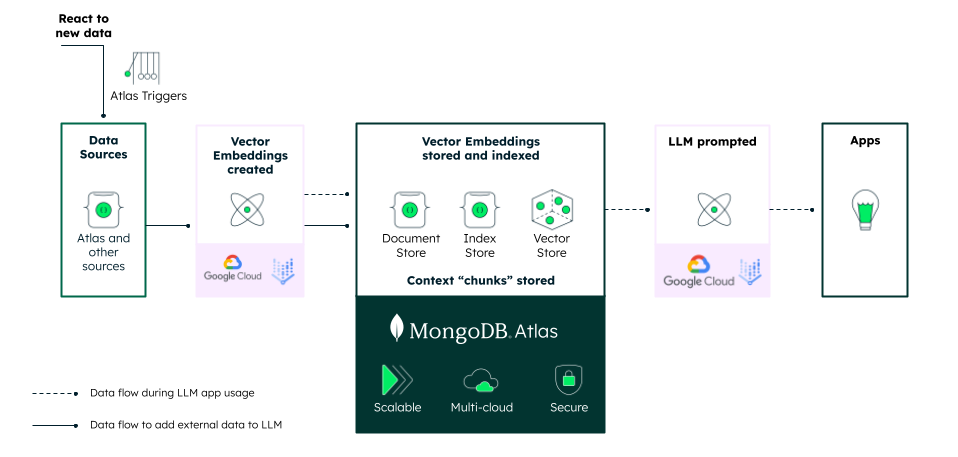
Vector search has changed what’s possible in terms of natural language interfaces. Because of the sheer number of vectors that a typical corpus would produce, many organizations are looking for specialized vector databases to store them. But storing your vectors apart from your operational database makes for inefficient applications. In a competitive marketplace, those efficiencies can cost you real money.
Ready to get started with MongoDB Atlas on Google Cloud? Check out our Google Cloud Marketplace listing to get started today or login to MongoDB Atlas. You can also learn more about our partnership on our Google integrations page.



