
SPONSORED BY IBM
We here at IBM have been researching and developing artificial intelligence hardware and software for decades—we created DeepBlue, which beat the reigning chess world champion, and Watson, a question-answering system that won Jeopardy! against two of the leading champions over a decade ago. Our researchers haven’t been coasting on these wins; they’ve been building new language models and optimizing how they are built and how they perform.
Obviously, the headlines around AI in the last few years have been dominated by generative AI and large-language models (LLM). While we’ve been working on our own models and frameworks, we’ve seen the impact these models have had—both good and bad. Our research has focused on how to make these technologies fast, efficient, and trustworthy. Both our partners and clients are looking to re-invent their own processes and experiences and we’ve been working with them. As companies look to integrate generative AI into their products and workflows, we want them to be able to take advantage of our decade-plus experience commercializing IBM Watson and how it’s helped us build our business-ready AI and data platform, IBM watsonx.
In this article, we’ll walk you through IBM’s AI development, nerd out on some of the details behind our new models and rapid inferencing stack, and take a look at IBM watsonx’s three components: watsonx.ai, watsonx.data, and watsonx.governance that together form an end-to-end trustworthy AI platform.

Origin story
Around 2018, we started researching foundation models in general. It was an exciting time for these models—there were lots of advancements happening—and we wanted to see how they could be applied to business domains like financial services, telecommunications, and supply chain. As it ramped up, we found many more interesting industry use cases based on years of ecosystem and client experience, and a group here decided to stand up a UI for LLMs to make it easier to explore. It was very cool to spend time researching this, but every conversation emphasized the importance of guardrails around AI for business.
Then in November 2022, OpenAI captured the public’s imagination with the release of ChatGPT. Our partners and clients were excited about the potential productivity and efficiency gains, and we began having more discussions with them around their AI for business needs. We set out to help clients capture the vast opportunity while keeping core principles of safety, transparency and trust at the core of our AI projects.
In our research, we were both developing our own foundation models and testing existing ones from others, so our platform was intentionally designed to be flexible about the models it supports. But now we needed to add the ability to run inference, tuning, and other model customizations, as well as create the underlying AI infrastructure stack to build foundation models from scratch. For that, we needed to hook up a data platform to the AI front end.
The importance of data
Data landscapes are complex and siloed, preventing enterprises from accessing, curating, and gaining full value from their data for analytics and AI. The accelerated adoption of generative AI will only amplify those challenges as organizations require trusted data for AI.
With the explosion of data in today’s digital era, data lakes are prevalent, but hard to efficiently scale. In our experience, data warehouses, especially in the cloud, are highly performant but are not the most cost effective. That is where the lakehouse architecture comes into play, based on price performant open source and low-cost object storage. For our data component, watsonx.data, we wanted to have something that would be both fast and cost efficient to unify governed data for AI.
The open data lakehouse architecture has been emerging in the past few years as a cloud-native solution to the limitations (and separation) of data lakes and data warehouses. The approach seemed the best fit for watsonx, as we needed a polyglot data store that could fulfill different needs of diverse data consumers. With watsonx.data, enterprises can simplify their data landscape with the openness of a lakehouse to access all of their data through a single point of entry and share a single copy of data across multiple query engines. This helps optimize price performance, de-duplication of data, and extract, transform and load (ETL). Organizations can unify, find, and prepare their data for the AI model or application of their choice.
Given IBM’s experience in databases with DB2 and Netezza, as well as in the data lake space with IBM Analytics Engine, BigSQL, and previously BigInsights, the lakehouse approach wasn’t a surprise, and we had been working on something in this vein for a few years. All things being equal, our clients would love to have a data warehouse hold everything, and just let it grow bigger and bigger. Watsonx.data needed to be on cost efficient, resilient commodity storage and handle unstructured data, as LLMs use a lot of raw text.
We brought in our database and data warehouse experts, who have been optimizing databases and analytical data warehouse for years, and asked “What does a good data lakehouse look like?” Databases in general try to store data so that the bytes on disk can be queried quickly, while data lakehouses need to efficiently consume the current generation of bytes on disk. Needing to optimize for data storage cost, as well, object storage offers that solution with the scale of its adoption and availability. But object stores don’t always have the best latency for the kind of high-frequency queries that AI applications require.
So how do we deliver better query performance on object storage? It’s basically a lot of clever caching on local NVMe drives. The object store that holds most of the data is relatively slow—measured in MBs per second—while the NVMe storage permits queries of GBs per second. Combine that with a database modified to use a private columnar table layout and Presto using Parquet, we get efficient table scanning and indices, and we can effectively compete with traditional warehouse performance, but tailored for AI workloads.
With the database design, we also had to consider the infrastructure. Performance, reliability, and data integrity are easier to manage for a platform when you own and manage the infrastructure—that’s why so many of the AI-focused database providers run either in managed clouds or as SaaS. With a SaaS product, you can tune your infrastructure so it scales well in a cost-effective manner.
But IBM has always been a hybrid company—not just SaaS, not just on-premise. Many enterprise companies don’t feel comfortable placing their mission-critical data in someone else’s datacenter. So we have to design for client-managed on-prem instances.
When we design for client-managed watsonx installs, we have a fascinating set of challenges from an engineering perspective. The instance could be a really small proof-of-concept, or it could scale to enterprise requirements around zero downtime, disaster recovery backups, multi-site resiliency—all those things an enterprise-scale business needs from a reliable platform. But they all necessarily require compatibility with an infrastructure architecture we don’t control. We have to provide the capabilities that the client wants in the form factor that they require.
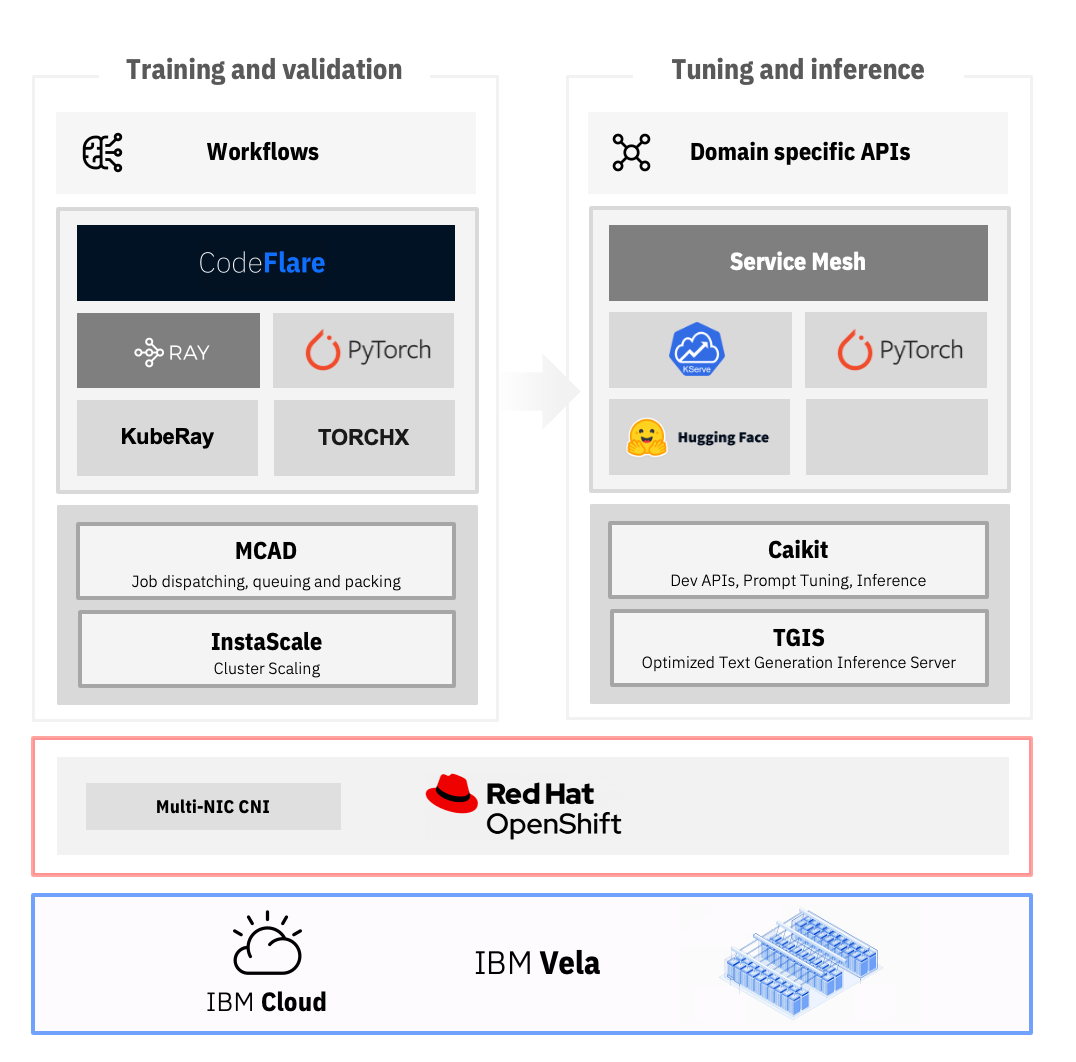
Key to providing reliability and consistency across instance types has been our support of open-source technologies. We’re all-in on PyTorch for model training and inference, and have been contributing our hardware abstraction and optimization work back into the PyTorch ecosystem. Additionally, Ray and CodeFlare have been instrumental in scaling those ML training workloads. KServe/ModelMesh/Service Mesh, Caikit, and Hugging Face Transformers helped with tuning and serving foundation models. And everything, from training to client-managed installs, runs on Red Hat OpenShift.
We were talking to a client the other day who saw our open-source stack and said, “It sounds like I could `pip install` a bunch of stuff and get to where you are.” We thought this through—sure you might be able to get your “Hello World” up, but are you going to cover scaling, high availability, self-serve by non-experts, access control, and address every new CVE?
We’ve been focusing on high-availability SaaS for about a decade, so we wake up in the morning, sip our coffee, and consider about complex systems in network-enabled environments. Where are you storing state? Is it protected? Will it scale? How do I avoid carrying too much state around? Where are the bottlenecks? Are we exposing the right embedding endpoints without leaving open backdoors?
Another one of the design tenets was creating a paved road for customers. The notion of a paved road is that we’re bringing our multi-enterprise experience to bear here, and we’re going to create the smoothest possible path to the end result as possible for our clients’ unique objectives.
Building LLMs, Dynamic inference, and optimization
Part of our paved road philosophy involves supplying foundation models, dynamic inferencing, and optimizations that we could stand behind. You can use any model you want from our foundation model library in watsonx, including Llama 2, StarCoder, and other open models. In addition to these well-known open models, we offer a complete AI stack that we’ve built based on years of our own research.
Our model team has been developing novel architectures that advance the state of the art, as well as building models using proven architectures. They’ve come up with a number of business-focused models that are currently or will soon be available on watsonx.ai:
- The Slate family are 153-million parameter multilingual non-generative encoder-only model based on the RoBERTa approach. While not designed for language generation, they efficiently analyze it for sentiment analysis, entity extraction, relationship detection, and classification tasks.
- The Granite models are based on a decoder-only architecture and are trained on enterprise-relevant datasets from five domains: internet, academic, code, legal and finance, all scrutinized to root out objectionable content, and benchmarked against internal and external models.
- Next year, we’ll be adding Obsidian models that use a new modular architecture developed by IBM Research designed to provide highly efficient inferencing. Our researchers are continuously working on other innovations such as modular architectures.
We say that these are models, plural, because we’re building focused models that have been trained on domain-specific data, including code, geospatial data, IT events, and molecules. For this training, we used our years of experience building AI supercomputers like Deep Blue, Watson, and Summit to create Vela, a cloud-native, AI-optimized supercomputer. Training multiple models was made easier thanks to the “LiGO” algorithm we developed in partnership with MIT. It uses multiple small models to build into larger models that take advantage of emergent LLM abilities. This method can save from 40-70% of the time, cost, and carbon output required to train a model.
As we see how generative AI is used in the enterprise, up to 90% of use cases involve some variant on retrieval-augmented generation (RAG). We found that even in our research on models, we had to be open to a variety of embeddings and data when it came to RAG and other post-training model customization.
Once we started applying models to our clients’ use cases, we realized there was a gap in the ecosystem: there wasn’t a good inferencing server stack in the open. Inferencing is where any generative AI spends most of its time—and therefore energy—so it was important to us to have something efficient. Once we started building our own—Text Generation Inferencing Service (TGIS), forked from Text Generation Inference—we found the hard problem around inferencing at scale is that requests come in at unpredictable times and GPU compute is expensive. You can’t have everybody line up perfectly and submit serial requests to be processed in order. No, the server would be halfway through one inferencing request doing GPU work and another request would come in. “Hello? Can I start doing some work, too?”
When we implemented batching on our end, it was dynamic and continuous as to make sure that the GPU was fully utilized at all times.
A fully utilized GPU here can feel like magic. Given intermittent arrival rates, different sizes of requests, different preemption rates, and different finishing times, the GPU can lay dormant as the rest of the system figures out which request to handle. When it takes maybe 50 milliseconds for the GPU to do something before you get your next token, we wanted the CPU to do as much smart scheduling to make sure those GPUs were doing the right work at the right time. So the CPU isn’t just queueing them up locally; it’s advancing the processing token by token.
If you’ve studied how compilers work, then this magic may seem a little more grounded in engineering and math. These requests and nodes to schedule can be treated like a graph. From there you can prune the graph, collapse or combine nodes, and perform other optimizations, like speculative decoding and other optimizations that reduce the amount of matrix multiplications that the GPUs have to tackle.
Those optimizations have given us improvements we can measure easily in the number of tokens per second. We’re working on stable quantization that reduces size and cost of inferencing in a highly/relatively lossless way, but the challenge has been getting all these optimizations into a single inference stack where they don’t cancel each other out. That’s happened: we’ve contributed a bunch to PyTorch optimization and then found a model quantization that gave us a great improvement.
We will continue to push the boundaries on inferencing performance, as it makes our platform a better business value. The reality is, though, that the inferencing space is going to commoditize pretty quickly. The real value to businesses will be how well they understand and control their AI products, and we think this is where watsonx.governance will make all the difference.
Governance
We’ve always strongly believed in the power of research to help ensure that any new capabilities we offer are trustworthy and business-ready. But when ChatGPT was released, the genie was out of the bottle. People were immediately using it in business situations and becoming very excited about the possibilities. We knew we had to build on our research and capabilities around ways to mitigate LLM downsides with proper governance: reducing things like hallucinations, bias, and the black box nature of the process.
With any business tool built on data, partners and clients have to be concerned about the risks involved in using those tools, not just the rewards. They’ll need to meet regulatory requirements around data use and privacy like GDPR and auditing requirements for processes like SOC 2 and ISO-27001, anticipate compliance with future AI-focused regulation, and mitigate ethical concerns like bias and legal exposure around copyright infringement and license violations.
For those of us working on watsonx, giving our clients confidence starts with the data that we use to train our foundation models. One of the things that IBM established early on with our partnership with MIT was a very large curated data set that we could train our Granite and other LLM models on while reducing legal risk associated with using them. As a company, we stand by this: IBM provides IP indemnification for IBM-developed watsonx AI models.
One of the big use cases for generative AI is code generation. Like a lot of models, we train on the GitHub Clean dataset and have a purpose-built Code Assistant as part of watsonx.
With such large data sets, LLMs are at risk of baking human biases into their model weights. Biases and other unfair results don’t show up until you start using the model. At that point, it’s very expensive to retrain a model to work out the biased training data. Our research teams have come up with a number of debiasing methods. These are just two of the approaches we use in eliminating biases from our models.
The Fair Infinitesimal Jackknife technique improves fairness by simply dropping carefully selected training data points in principle, but without retrofitting the model. It uses a version of the jackknife technique adapted to machine learning models that leaves out an observation from calculations and aggregating the remaining results. This simple statistical tool greatly increases fairness without affecting the results the model provides.
The FairReprogram approach likewise does not try to modify the base model; it considers the weights and parameters fixed. When the LLM produces something that trips the unfairness trigger, FairReprogram introduces false demographic information into the input that can effectively obscure demographic biases by preventing the model from using the biased demographic information to make predictions.
These interventions, while we consider they make our AI and data platform more trustworthy, don’t let you audit how the AI produced a result. For that, we extended our OpenScale platform to cover generative AI. This helps provide explainability that’s been missing from a lot of generative AI tools—you can see what’s going on in the black box. There’s a ton of data we provide: confusion and confidence ratings to see if the model analyzed your transaction correctly, references to the training data, views of what this result would look like after debiasing, and more. Testing for generative AI errors is not always straightforward and can involve statistical analyses, so being able to trace errors more efficiently lets you correct them better.
What we said early about being a hybrid cloud company and allowing our clients to swap in models and pieces of the stack applies to governance as well. Clients may pick a bunch of disparate technologies and expect them all to work. They expect our governance tools to work with any given LLM, including custom ones. The odds of someone picking a stack entirely composed of technology we’ve tested ahead of time is pretty slim. So we had to take a look at our interfaces and make sure they were widely adoptable.
From an architecture perspective, this meant separating the pieces out and abstracting the interfaces to them—this piece does inference, this does code, etc. We also couldn’t assume that any payloads would be forwarded to governance by default. The inference and monitoring paths have to be separated out so if there are shortcuts available for data gathering, that’s great. But if not, there are ways to register intent. We’re working with major providers so that we know about any payload hooks in their tech. But a client using something custom or boutique may have to do a little stitching to get everything working. Worst case scenario is you manually call governance after LLM calls to let it know what the AI is doing.
We know that professional developers are a little wary about generative AI (and Stack Overflow does too), so we believe that any AI platform has to be open and transparent in how they are created and run. Our commitment to open source is part of that, but so is our commitment to lowering the risk of adopting these powerful new generative tools. AI you can trust doing business with.
The possibilities of generative AI are very exciting, but the potential pitfalls can keep businesses from adopting it. We at IBM built all three components of watsonx — watsonx.ai, watsonx.data and watsonx.governance — to be something our enterprise clients could trust and would not be more trouble than they’re worth.
Build with IBM watsonx today
Whether you’re an up-and-coming developer or seasoned veteran, learn how you can start building with IBM watsonx today.



